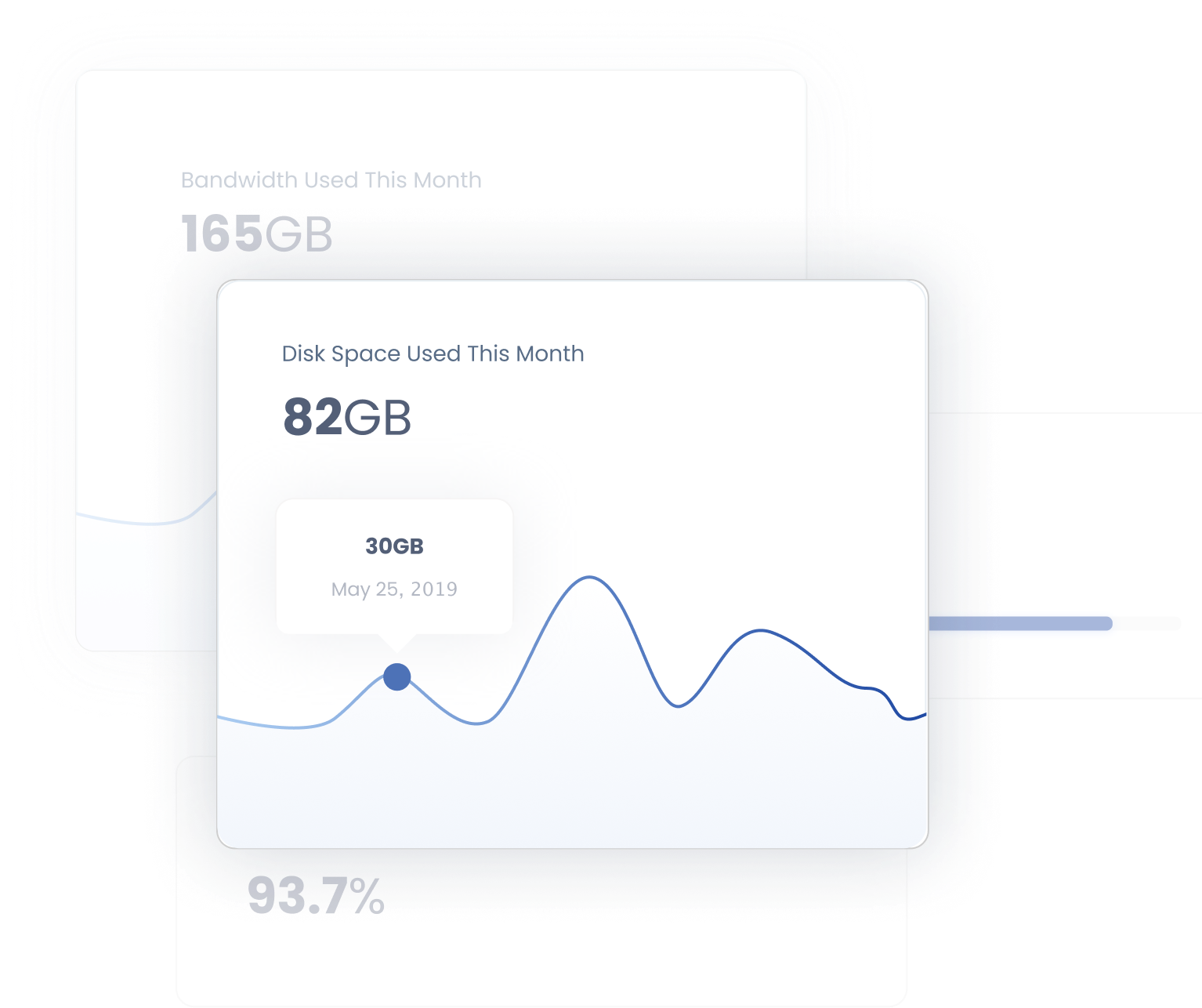
Why am I not storing more data?
The most important aspect to increase the amount of data stored on your Node (and thus maximizing payout) is to build reputation of your Node’s ID over an extended period of time**.**
When a Node first joins the network, there is a probationary period, during which the Node has to prove itself (e.g. maintaining a certain uptime and performance levels, passing all content audits). During that vetting period, the Node only receives as small amount of non-critical data (but still gets paid for this data). Once vetted, a Node can start receiving more data (and not just test data), but must continue to maintain uptime and audit requirements to avoid disqualification.
The filtering system blocks bad Storage Nodes from participating. Additional actions that are disqualifying include: failing too many audits; failing to return data, with reasonable speed; and failing too many uptime checks.
After disqualified Storage Nodes have been filtered out, remaining statistics collected during audits are used to establish a preference for better Storage Nodes during uploads. These statistics include performance characteristics such as throughput and latency, history of reliability and uptime, geographic location, and other desirable qualities. They are combined into a load-balancing selection process, such that all uploads are sent to qualified Nodes, with a higher likelihood of uploads to preferred Nodes, but with a non-zero chance for any qualified Node.